
{kind=link}

(Yurchanka-Siarhei/Shutterstock)
When Cloudflare reached the limits of what its existing ELT tool could do, the company had a decision to make. It could try and find a an existing ELT tool that could handle its unique requirements, or it could build its own. After considering the options, Cloudflare chose to build its own big data pipeline framework, which it calls Jetflow.
Cloudflare is a trusted global provider of security, network, and content delivery solutions used by thousands of organizations around the world. It protects the privacy and security of millions of users every day, making the Internet a safer and more useful place.
With so many services, it’s not surprising to learn that the company piles up its share of data. Cloudflare operates a petabyte-scale data lake that is filled with thousands of database tables every day from Clickhouse, Postgres, Apache Kafka, and other data repositories, the company said in a blog post last week.
“These tasks are often complex and tables may have hundreds of millions or billions of rows of new data each day,” the Cloudflare engineers wrote in the blog. “In total, about 141 billion rows are ingested every day.”
When the volume and complexity of data transformations exceeded the capability its existing ELT product, Cloudflare decided to replace it with something that could handle it. After evaluating the market for ELT solutions, Cloudflare realized that there were nothing that was commonly available was going to fit the bill.

Image courtesy Cloudflare
“It became clear that we needed to build our own framework to cope with our unique requirements–and so Jetflow was born,” the Cloudflare engineers wrote.
Before laying down the first bits, the Cloudflare team set out its requirements. The company needed to move data into its data lake in a streaming fashion, as the previous batch-oriented system sometimes exceeded 24 hours, preventing daily updates. The amount of compute and memory also should come down.
Backwards compatibility and flexibility were also paramount. “Due to our usage of Spark downstream and Spark’s limitations in merging disparate Parquet schemas, the chosen solution had to offer the flexibility to generate the precise schemas needed for each case to match legacy,” the engineers wrote. Integration with its metadata system was also required.
Cloudflare also wanted the new ELT tools’ configuration files to be version controlled, and not to become a bottleneck when many changes are made concurrently. Ease-of-use was another consideration, as the company planned to have people with different roles and technical abilities to use it.
“Users should not have to worry about availability or translation of data types between source and target systems, or writing new code for each new ingestion,” they wrote. “The configuration needed should also be minimal–for example, data schema should be inferred from the source system and not need to be supplied by the user.”
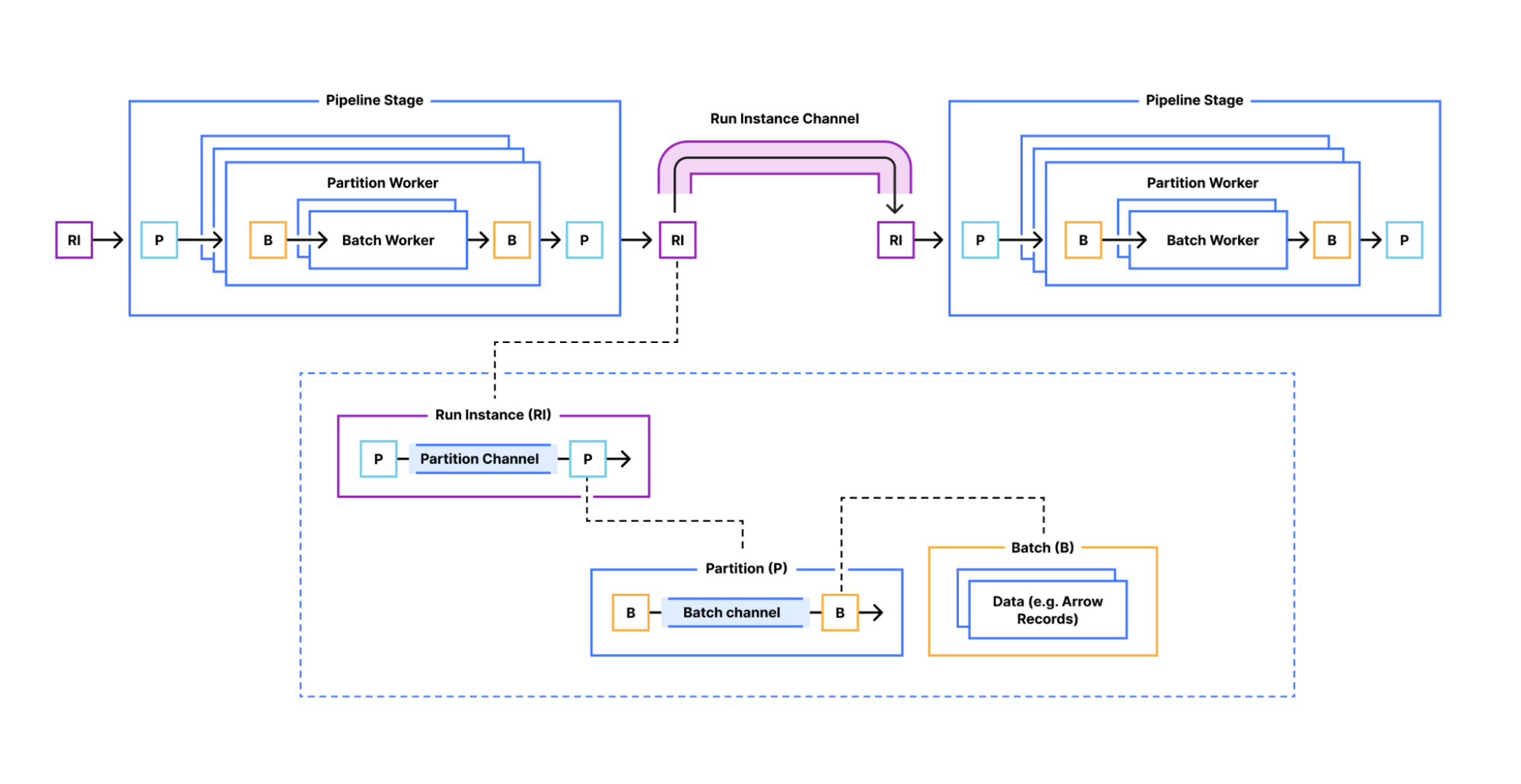
Jetflow is an ELT tool from Cloudflare (Image courtesy Cloudflare)
At the same time, Cloudflare wanted the new ELT tool to be customizable, and to have the option of tuning the system to handle specific use cases, such as allocating more resources to handle writing Parquet files (which is a more resource-heavy task than reading Parquet files). The engineers also wanted to be able to spin up concurrent workers in different threads, different containers, or on different machines, on an as-needed basis.
Lastly, they wanted the new ELT tool to be testable. Engineers wanted to enable users to be able to write tests for every stage of the data pipeline to ensure that all edge cases are accounted for before promoting a pipeline into production.
The resulting Jetflow framework is a streaming data transformation system that is broken down into consumers, transformers, and loaders. The data pipeline is created as a YAML file, and the three stages can be independently tested.
The company designed Jetflow’s parallel data processing capabilities to be idempotent (or internally consistent) both on whole pipeline re-runs as well as with retries of updates to any particular table due to an error. It also features a batch mode, which provides chunking of large data sets down into smaller pieces for more efficient parallel stream processing, the engineers write.
One of the biggest questions the Cloudflare engineers faced was how to ensure compatibility with the various Jetflow stages. Originally the engineers wanted to create a custom type system that would allow stages to output data in multiple data formats. That turned into a “painful learning experience,” the engineers wrote, and led them to keep each stage extractor class working with just one data format.
The engineers selected Apache Arrow as its internal, in-memory data format. Instead of an inefficient process of reading row-based data and then converting it into the columnar format, which are used to generate Parquet files (its primary data format for its data lake), Cloudflare makes an effort to ingest data in column formats in the first place.![]()
This paid dividends for moving data from its Clickhouse data warehouse into the data lake. Instead of reading data using Clickhouse’s RowBinary format, Jetflow reads data using Clickhouse’s Blocks format. By using the ch-go low level library, Jetflow is able to ingest millions of rows of data per second using a single Clickhouse connection.
“A valuable lesson learned is that as with any software, tradeoffs are often made for the sake of convenience or a common use case that may not match your own,” the Cloudflare engineers wrote. “Most database drivers tend not to be optimized for reading large batches of rows, and have high per-row overhead.”
The Cloudflare team also made a strategic decision when it came to the type of Postgres database driver to use. They use the jackc/pgx driver, but bypassed the database/sql Scan interface in favor of receiving raw data for each row and using the jackc/pgx internal scan functions for each Postgres OID. The resulting speedup allows Cloudflare to ingest about 600,000 rows per second with low memory usage, the engineers wrote.
Currently, Jetflow is being used to ingest 77 billion records per day into the Cloudflare data lake. When the migration is complete, it will be running 141 billion records per day. “The framework has allowed us to ingest tables in cases that would not otherwise have been possible, and provided significant cost savings due to ingestions running for less time and with fewer resources,” the engineers write.
The company plans to open source Jetflow at some point in the future.
Related Items:
ETL vs ELT for Telemetry Data: Technical Approaches and Practical Tradeoffs
Exploring the Top Options for Real-Time ELT
50 Years Of ETL: Can SQL For ETL Be Replaced?