
{kind=link}
As humans, we learn to do new things, like ballet or boxing (both activities I had the opportunity to try this summer!), through trial and error. We improve by trying things out, learning from our mistakes, and listening to guidance. I know this feedback loop well—part of my intern project for the summer was teaching a reward model to identify better code fixes to show users, as part of Databricks’ effort to build a top-tier Code Assistant.
However, my model wasn’t the only one learning through trial and error. While teaching my model to distinguish good code fixes from bad ones, I learned how to write robust code, balance latency and quality concerns for an impactful product, clearly communicate to a larger team, and most of all, have fun along the way.
Databricks Assistant Quick Fix
If you’ve ever written code and tried to run it, only to get a pesky error, then you would appreciate Quick Fix. Built into Databricks Notebooks and SQL Editors, Quick Fix is designed for high-confidence fixes that can be generated in 1-3 seconds—ideal for syntax errors, misspelled column names, and simple runtime errors. When Quick Fix is triggered, it takes code and an error message, then uses an LLM to generate a targeted fix to solve the error.
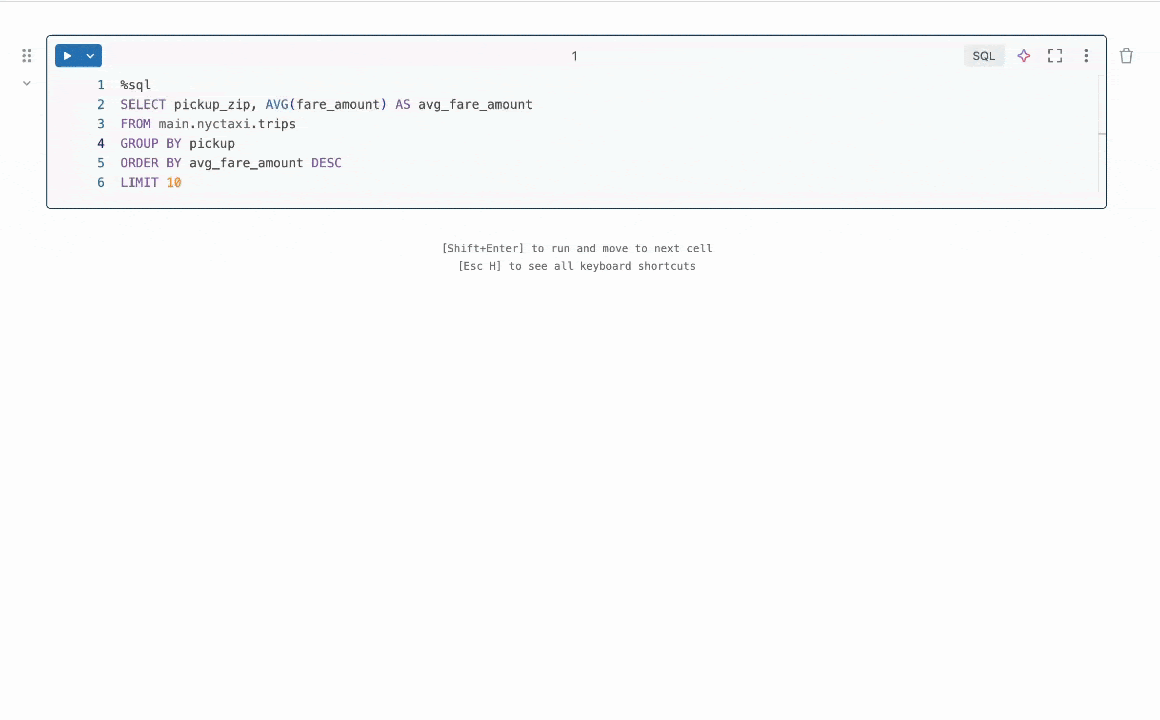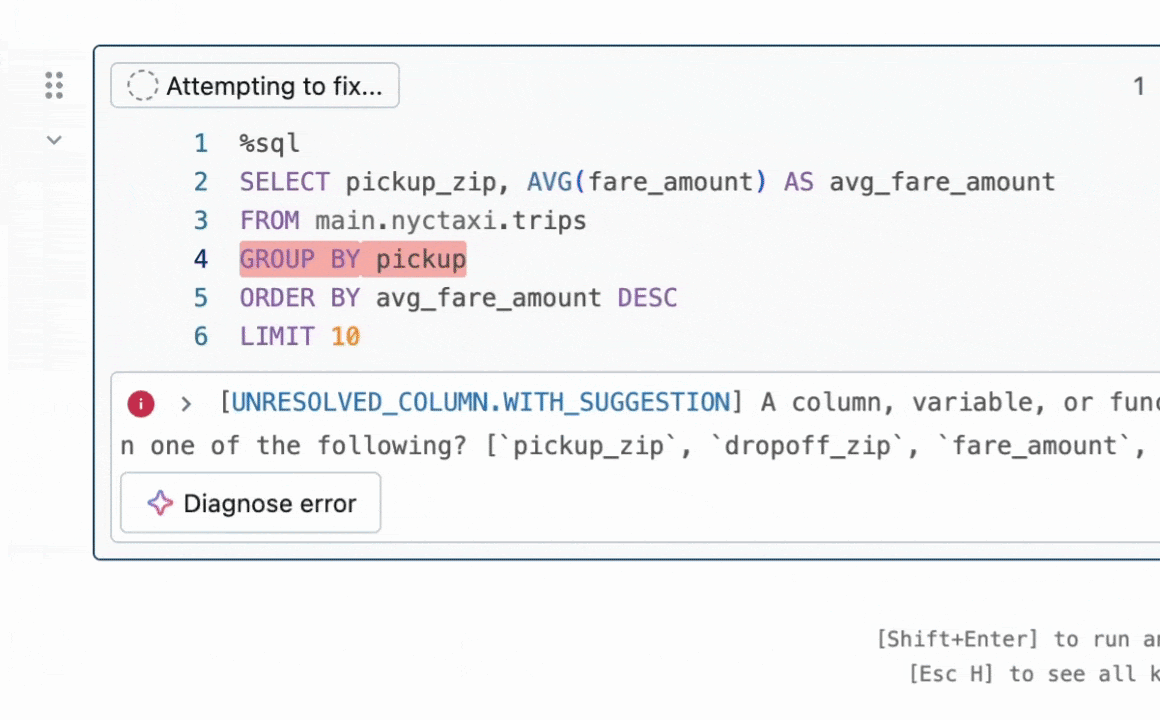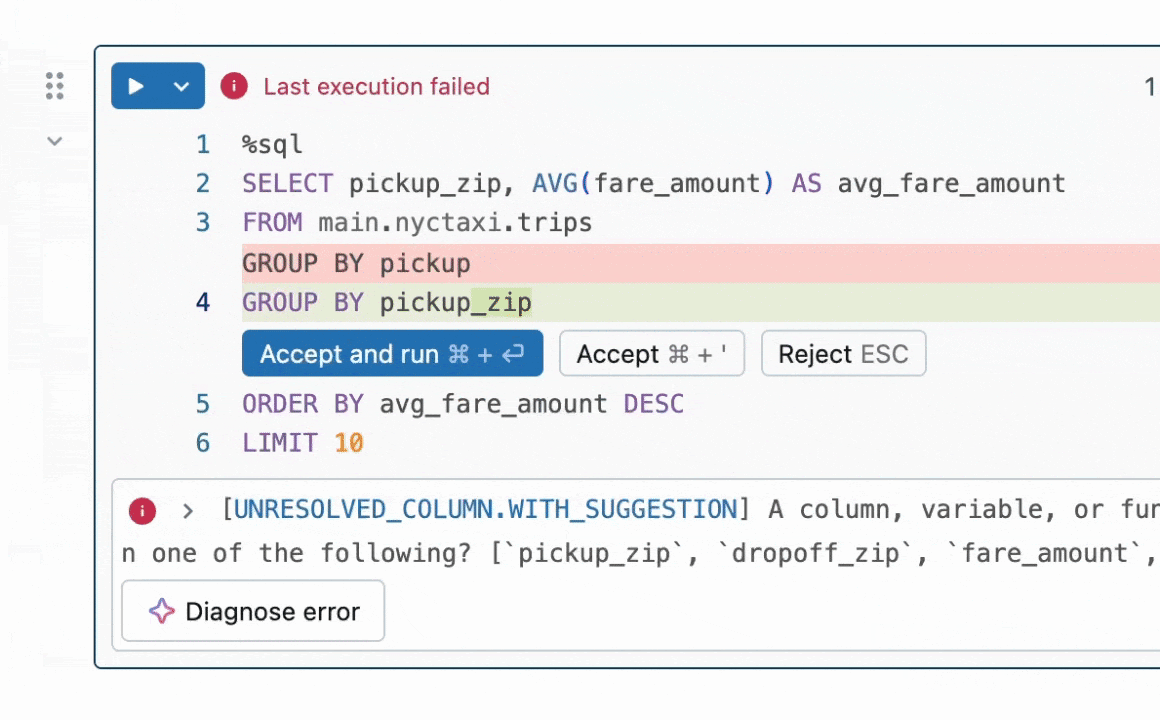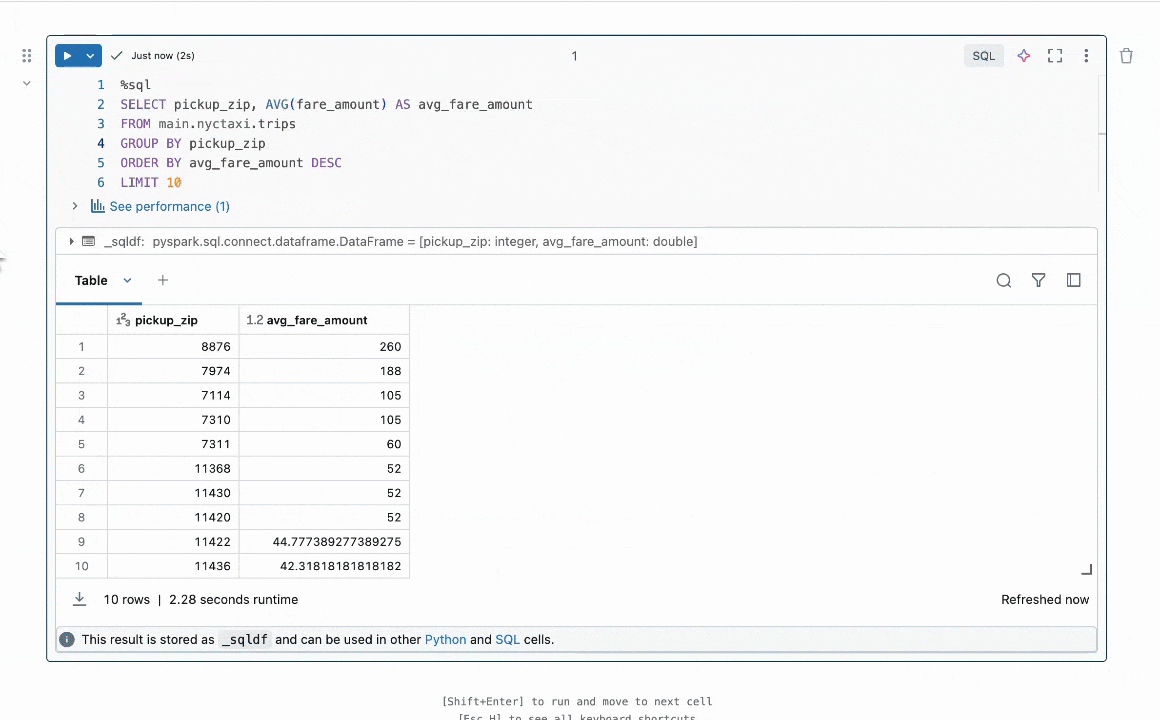
What problem did my intern project tackle?
While Quick Fix already existed and was helping Databricks users fix their code, there were plenty of ways to make it even better! For example, after we generate a code fix and do some basic checks that it passes syntax conventions, how can we ensure that the fix we end up showing a user is the most relevant and accurate? Enter best-of-k sampling—generate multiple possible fix suggestions, then use a reward model to choose the best one.
My project structure
My project involved a mix of backend implementation and research experimentation, which I found to be fun and full of learning.

Generating multiple suggestions
I first expanded the Quick Fix backend flow to generate diverse suggestions in parallel using different prompts and contexts. I experimented with techniques like adding chain-of-thought reasoning, predicted outputs reasoning, system prompt variations, and selective database context to maximize the quality and diversity of suggestions. We found that generating suggestions with additional reasoning increased our quality metrics but also induced some latency cost.
Choosing the best fix suggestion to show to the user
After multiple suggestions are generated, we have to choose the best one to return. I started by implementing a simple majority voting baseline, which presented the user with the most frequently suggested fix—operating on the principle that a more commonly generated solution would likely be the most effective. This baseline performed well in the offline evaluations but did not perform significantly better than the current implementation in online user A/B testing, so it was not rolled out to production.
Additionally, I developed reward models to rank and select the most promising suggestions. I trained the models to predict which fixes users would accept and successfully execute. We used classical machine learning approaches (logistic regression and gradient boosted decision tree using the LightGBM package) and fine-tuned LLMs.
Results and impact
Surprisingly, for the task of predicting user acceptance and execution success of candidate fixes, the classical models performed comparably to the fine-tuned LLMs in offline evaluations. The decision tree model in particular might have performed well because code edits that “look right” for the kinds of errors that Quick Fix handles tend to in fact be correct: the features that turned out to be particularly informative were the similarity between the original line of code and the generated fix, as well as the error type.
Given this performance, we decided to deploy the decision tree (LightGBM) model in production. Another factor in favor of the LightGBM model was its significantly faster inference time compared to the fine-tuned LLM. Speed is critical for Quick Fix since suggestions must appear before the user manually edits their code, and any additional latency means fewer errors fixed. The small size of the LightGBM model made it much more resource efficient and easier to productionize—alongside some model and infrastructure optimizations, we were able to decrease our average inference time by almost 100x.
With the best-of-k approach and reward model implemented, we were able to raise our internal acceptance rate, increasing quality for our users. We were also able to keep our latency within acceptable bounds of our original implementation.
If you want to learn more about the Databricks Assistant, check out the landing page or the Assistant Quick Fix Announcement.
My Internship Experience
Databricks culture in action
This internship was an incredible experience to contribute directly to a high-impact product. I gained firsthand insight into how Databricks’ culture encourages a strong bias for action while maintaining a high bar for system and product quality.
From the start, I noticed how intelligent yet humble everyone was. That impression only grew stronger over time, as I saw how genuinely supportive the team was. Even very senior engineers regularly went out of their way to help me succeed, whether by talking through technical challenges, offering thoughtful feedback, or sharing their past approaches and learnings.
I’d especially like to give a shoutout to my mentor Will Tipton, my managers Phil Eichmann and Shanshan Zheng, my informal mentors Rishabh Singh and Matt Hayes, the Editor / Assistant team, the Applied AI team, and the MosaicML folks for their mentorship. I’ve learned invaluable skills and life lessons from them, which I will take with me for the rest of my career.
The other awesome interns!
Last but not least, I had a great time getting to know the other interns! The recruiting team organized many fun events that helped us connect—one of my favorites was the Intern Olympics (pictured below). Whether it was chatting over lunch, trying out local workout classes, or celebrating birthdays with karaoke, I really appreciated how supportive and close-knit the intern group was, both in and outside of work.

Intern Olympics! Go Team 2!

Shout-out to the other interns who tried boxing with me!
This summer taught me that the best learning happens when you’re solving real problems with real constraints—especially when you’re surrounded by smart, driven, and supportive people. The most rewarding part of my internship wasn’t just completing model training or presenting interesting results to the team, but realizing that I’ve grown in my ability to ask better questions, reason through design trade-offs, and deliver a concrete feature from start to finish on a platform as widely used as Databricks.
If you want to work on cutting-edge projects with amazing teammates, I’d recommend you to apply to work at Databricks! Visit the Databricks Careers page to learn more about job openings across the company.