
{kind=link}
OpenAI has released two open-source language models, gpt-oss-120b and gpt-oss-20b. These are OpenAI’s first openly licensed LLMs since GPT-2. Aiming to create the best state-of-the-art reasoning and tool-use models available. The models were launched to considerable fanfare in the AI community.
By open-sourcing gpt-oss, OpenAI allows people to freely use and adapt within the bounds of Apache 2.0. These two models certainly consider a democratic approach for professional personalization and customization of the technology to local, contextual tasks. In this article guide, we’ll go through how to access gpt-oss-120b and gpt-oss-20b, and when to use which model.
What Makes gpt-oss Special?
OpenAI’s new open-weight models are the most robust public models since GPT-2. It uses the latest approaches from the most advanced systems and is built to really work and be easy to use and adapt.
- Open Apache 2.0 License: The gpt-oss models are both entirely open-weight models and are licensed under the permissive Apache 2.0 license. This means there are no copyleft restrictions and developers can use them for research or commercial products with no licensing fees or source-code obligations.
- Configurable Reasoning Levels: A unique feature is the ease of configuring the model’s reasoning effort: low, medium, or high. This is a trade-off of speed vs. depth. A simple system message like “Use low reasoning” or “Use high reasoning” will make the model think less or more deeply before it answers.
- Full Chain-of-Thought Access: Unlike many closed models, gpt-oss shows its internal reasoning. It has a default output of an analysis, i.e, reasoning steps channel, followed by a final answer channel. Users and developers can inspect or filter the portion to debug or trust the model’s reasoning.
- Native Agentic Capabilities: These models are built on an agentic workflow. They are built towards instruction-following, and they are built with native support for using tools in their thinking.
Model Overview & Architecture
Both gpt-oss models are Transformer-based networks employing a Mixture-of-Experts (MoE) design. In an MoE, only a subset of the full parameters (“experts”) is active for each input token, reducing computation. In terms of numbers:
- gpt-oss-120b has 117 billion total parameters (36 layers). It uses 128 expert sub-networks, with 4 experts active per token. This results in only ~5.1 billion active parameters per token.
- gpt-oss-20b has 21 billion total parameters (24 layers) with 32 experts (4 active), yielding ~3.6 billion active parameters per token.
The architecture also includes several advanced features: all attention layers use Rotary Positional Embeddings (RoPE) to handle very long contexts (up to 128,000 tokens). Attention itself alternates between a full-global and a 128-token sliding window, similar to GPT-3’s design.
These models use grouped multi-query attention with a group size of 8 to save memory while maintaining fast inference. Activations are SwiGLU. Importantly, all expert weights are quantized to a 4-bit MXFP4 format, allowing the large model to fit in one 80GB GPU and the smaller model in 16GB without a major accuracy loss.
The table below summarizes the core specs:
| Model | Layers | Total Params | Active Params/Token | Experts (total/active) | Context |
|---|---|---|---|---|---|
| gpt-oss-120b | 36 | 117B | 5.1B | 128 / 4 | 128K |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 / 4 | 128K |
Technical Specifications & Licensing
- Hardware Requirements: gpt-oss-120b needs a high-end GPU (~80–100 GB VRAM) and runs on a single 80 GB A100/H100-class GPU or multi-GPU setups. gpt-oss-20b is lighter, running in ~16 GB VRAM even on laptops or Apple Silicon. Both models support 128K token contexts, ideal for long documents but compute-intensive.
- Quantization & Performance: Both models use 4-bit MXFP4 as the default, which helps in reducing memory use and speeding up inference. However, without compatible hardware, they fall back to 16-bit and require approximately ~48 GB for gpt-oss-20b. Speed can be further improved using optional advanced kernels like FlashAttention.
- License & Usage: Released under Apache 2.0, both models can be used, modified, and distributed freely, even for commercial use, with no royalties or code-sharing requirements. No API fees or license restrictions apply.
| Specification | gpt-oss-120b | gpt-oss-20b |
|---|---|---|
| Total Parameters | 117 billion | 21 billion |
| Active Parameters per Token | 5.1 billion | 3.6 billion |
| Architecture | Mixture-of-Experts with 128 experts (4 active/token) | Mixture-of-Experts with 32 experts (4 active/token) |
| Transformer Blocks | 36 layers | 24 layers |
| Context Window | 128,000 tokens | 128,000 tokens |
| Memory Requirements | 80 GB (fits on a single H100 GPU) | 16 GB |
Installation and Setup Process
Here are the ways to get started with gpt-oss:
1. Hugging Face Transformers: Install the latest libraries and load the model directly. The following command installs the necessary prerequisites:
pip install --upgrade accelerate transformersThe code below downloads the required model from the Hugging Face hub.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
model = AutoModelForCausalLM.from_pretrained(
"openai/gpt-oss-20b", device_map="auto", torch_dtype="auto")Once the model has been downloaded, you can test it out using:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain why the sky is blue."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))This setup was documented in OpenAI’s guide and runs on any GPU. (For best speed on NVIDIA A100/H100 cards, install triton kernels to use MXFP4; otherwise the model will use 16-bit internally).
2. vLLM: For high-throughput or multi-GPU serving, you can use the vLLM library. OpenAI notes that on 2x H100s. You can install vLLM using:
pip install vllmOne can start a server with:
vllm serve openai/gpt-oss-120b --tensor-parallel-size 2Or in Python:
from vllm import LLM
llm = LLM("openai/gpt-oss-120b", tensor_parallel_size=2)
output = llm.generate("San Francisco is a")
print(output)This uses optimized attention kernels on Hopper GPUs.
3. Ollama (Local on Mac/Windows): Ollama is a turnkey local chat server. After installing Ollama, simply run:
ollama pull gpt-oss:20b
ollama run gpt-oss:20bThis will download the model (quantized) and launch a chat UI. Ollama auto-applies a chat template (the “harmony” format) by default. You can also call it via API. For example, using Python and the OpenAI SDK pointed at Ollama’s endpoint:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = client.chat.completions.create(
model="gpt-oss:20b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain what MXFP4 quantization is."}
]
)
print(response.choices[0].message.content)This sends the prompt to the local gpt-oss model, just like the official API.
4. Llama.cpp (CPU/ARM): Pre-built GGUF versions of the models are available (e.g, ggml-org/GPT-Oss-120b-GGUF on Hugging Face). After installing llama.cpp, you can serve the model locally:
# macOS:
brew install llama.cpp
# Start a local HTTP server for inference:
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 -fa --jinja --reasoning-format noneThen send chat messages to http://localhost:8080 in the same format. This option allows running even on a CPU or GPU-agnostic environment with JIT or Vulkan support.
Overall, gpt-oss models can be used with most common frameworks. The above methods (Transformers, vLLM, Ollama, llama.cpp) cover desktop and server setups. You can mix and match – for instance, run one setup for fast inference (vLLM on GPU) and another for on-device testing (Ollama or llama.cpp).
Hands-On Demo Section
Task 1: Reasoning Task
Prompt: “”” Select the option that is related to the third term in the same way as the second term is related to the first term.
IVORY : ZWSPJ :: CREAM : ?
A. NFDQB
B. SNFDB
C. DSFCN
D. BQDZL
”””
import os
os.environ['HF_TOKEN'] = 'HF_TOKEN'
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = client.chat.completions.create(
model="openai/GPT-Oss-20b", # openai/GPT-Oss-120b Change to use 120b model
messages=[
{
"role": "user",
"content": """Select the option that is related to the third term in the same way as the second term is related to the first term.
IVORY : ZWSPJ :: CREAM : ?
A. NFDQB
B. SNFDB
C. DSFCN
D. BQDZL
"""
}
],
)
# Check if there's content in the main content field
if completion.choices[0].message.content:
print("Content:", completion.choices[0].message.content)
else:
# If content is None, check reasoning_content
print("Reasoning Content:", completion.choices[0].message.reasoning_content)
# For Markdown display in Jupyter
from IPython.display import display, Markdown
# Display the actual content that exists
content_to_display = (completion.choices[0].message.content or
completion.choices[0].message.reasoning_content or
"No content available")gpt-oss-120b Response:
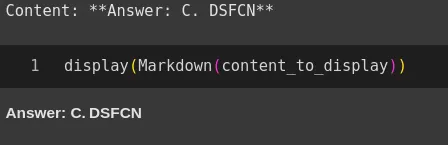
gpt-oss-20b Response:

Comparative Analysis
gpt-oss-120B correctly identifies the relevant pattern in the analogy and selects option C with deliberate reasoning. Since it methodically interprets the character transformation between word pairs to obtain the correct mapping. On the other hand, gpt-oss-20B fails to yield any result on this task, likely due to the limits of the output tokens.
This might suggest difficulties with output length, as well as computational inefficiencies. Overall, gpt-oss-120B is better able to manage symbolic reasoning with much more control and accuracy; therefore, it is more reliable than gpt-oss-20B for this reasoning task involving verbal analogy.
Task 2: Code Generation
Prompt: “”” Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays.
The overall run time complexity should be O(log (m+n)) in C++.
Example 1:
Input: nums1 = [1,3], nums2 = [2]
Output: 2.00000
Explanation: merged array = [1,2,3] and median is 2.
Example 2:
Input: nums1 = [1,2], nums2 = [3,4]
Output: 2.50000
Explanation: merged array = [1,2,3,4] and median is (2 + 3) / 2 = 2.5.
Constraints:
nums1.length == m
nums2.length == n
0 <= m <= 1000
0 <= n <= 1000
1 <= m + n <= 2000
-106 <= nums1[i], nums2[i] <= 106
”””
import os
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = client.chat.completions.create(
model="openai/GPT-Oss-120b", # openai/GPT-Oss-20b change to use 20b model
messages=[
{
"role": "user",
"content": """Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays.
The overall run time complexity should be O(log (m+n)) in C++.
Example 1:
Input: nums1 = [1,3], nums2 = [2]
Output: 2.00000
Explanation: merged array = [1,2,3] and median is 2.
Example 2:
Input: nums1 = [1,2], nums2 = [3,4]
Output: 2.50000
Explanation: merged array = [1,2,3,4] and median is (2 + 3) / 2 = 2.5.
Constraints:
nums1.length == m
nums2.length == n
0 <= m <= 1000
0 <= n <= 1000
1 <= m + n <= 2000
-106 <= nums1[i], nums2[i] <= 106
"""
}
],
)
# Check if there's content in the main content field
if completion.choices[0].message.content:
print("Content:", completion.choices[0].message.content)
else:
# If content is None, check reasoning_content
print("Reasoning Content:", completion.choices[0].message.reasoning_content)
# For Markdown display in Jupyter
from IPython.display import display, Markdown
# Display the actual content that exists
content_to_display = (completion.choices[0].message.content or
completion.choices[0].message.reasoning_content or
"No content available")gpt-oss-120b Response
include <bits/stdc++.h>
using namespace std;
class Solution {
public:
double findMedianSortedArrays(const vector<int>& nums1,
const vector<int>& nums2) {
// Let A be the shorter array.
const vector<int>* A = &nums1;
const vector<int>* B = &nums2;
if (A->size() > B->size()) swap(A, B); // now |A| ≤ |B|
int m = A->size();
int n = B->size();
int total = m + n;
int half = (total + 1) / 2; // size of left part
int low = 0, high = m; // we search over number of elements taken from A
while (low <= high) {
int i = (low + high) / 2; // elements from A on the left side
int j = half - i; // must come from B
// Edge handling: use infinities for out‑of‑range indices
int a_left = (i == 0 ? INT_MIN : (*A)[i - 1]);
int a_right = (i == m ? INT_MAX : (*A)[i]);
int b_left = (j == 0 ? INT_MIN : (*B)[j - 1]);
int b_right = (j == n ? INT_MAX : (*B)[j]);
if (a_left > b_right) { // i too large
high = i - 1;
} else if (b_left > a_right) { // i too small
low = i + 1;
} else { // correct split
int max_left = max(a_left, b_left);
if (total % 2 == 1) // odd
return static_cast<double>(max_left);
int min_right = min(a_right, b_right);
return (max_left + min_right) / 2.0;
}
}
// The code never reaches here because the constraints guarantee at least one element.
return 0.0;
}
};
/* Example usage
int main() {
Solution s;
vector<int> a = {1, 3};
vector<int> b = {2};
cout << fixed << setprecision(5) << s.findMedianSortedArrays(a, b) << endl; // 2.00000
a = {1,2};
b = {3,4};
cout << fixed << setprecision(5) << s.findMedianSortedArrays(a, b) << endl; // 2.50000
}gpt-oss-20b Response
# Reference Implementation (C++17)
include <bits/stdc++.h>
using namespace std;
class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1,
vector<int>& nums2) {
// Ensure nums1 is the shorter array
if (nums1.size() > nums2.size())
return findMedianSortedArrays(nums2, nums1);
int m = nums1.size();
int n = nums2.size();
int low = 0, high = m;
int halfLen = (m + n + 1) / 2; // size of left part
while (low <= high) {
int i = (low + high) / 2; // partition in nums1
int j = halfLen - i; // partition in nums2
// i too small - must move right
if (i < m && nums2[j-1] > nums1[i])
low = i + 1;
// i too big - must move left
else if (i > 0 && nums1[i-1] > nums2[j])
high = i - 1;
else {
// correct partition found
int maxLeft;
if (i == 0)
maxLeft = nums2[j-1];
else if (j == 0)
maxLeft = nums1[i-1];
else
maxLeft = max(nums1[i-1], nums2[j-1]);
// odd total, median is maxLeft
if ((m + n) % 2 == 1)
return static_cast<double>(maxLeft);
// even total, need minRight as well
int minRight;
if (i == m)
minRight = nums2[j];
else if (j == n)
minRight = nums1[i];
else
minRight = min(nums1[i], nums2[j]);
return (maxLeft + minRight) / 2.0;
}
}
// Should never reach here for valid input
return 0.0;
}
};
/* Example usage:
int main() {
Solution s;
vector<int> a = {1, 3};
vector<int> b = {2};
cout << fixed << setprecision(5) << s.findMedianSortedArrays(a, b) << endl; // 2.00000
}Comparative Analysis
gpt-oss-120B completes the analogy accurately, selecting option C, and shows strong rationale by successfully identifying the letter substitution pattern. The model shows good reasoning in terms of handling shifts in the letters’ oscillatory and keeping track of relationships between things. On the other hand, gpt-oss-20B is unable to even complete the task! The model exceeded the output token limit and did not return an answer. This indicates gpt-oss-20B is inefficient in either its resource usage or its handling of the prompt. Overall, gpt-oss-120B demonstrates much better performance in structured reasoning tasks, making it a much better choice than gpt-oss-20B for tasks related to symbolic analogies.
Model Selection Guide
Choosing between the 120B and 20B models depends on the needs of one’s project or the task on which we are working:
- gpt-oss-120b: This is the high-power model. Use it for the hardest reasoning tasks, complex code generation, math problem solving, or domain-specific Q&A. It performs close to OpenAI’s o4-mini model. Therefore, it needs a large GPU with roughly 80GB+ VRAM to run it and excels on benchmarks and long-form tasks where step-by-step reasoning is crucial.
- gpt-oss-20b: This is a “workhorse” model optimized for efficiency. It matches the quality of OpenAI’s o3-mini on many benchmarks, but can run on a single 16GB VRAM. Choose 20B when you need a fast on-device assistant, low-latency chatbot, or tools that use web search/Python calls. It’s ideal for proof-of-concepts, mobile/edge applications, or when hardware is constrained. In many cases, the 20B model answers well enough. For example, it scored ~96% on a difficult math contest task, nearly matching 120B.
Performance Benchmarks and Comparisons
On standard benchmarks, OpenAI’s gpt-oss shares results. The 120B model works its way upward, scoring higher than the 20B model on tough reasoning and knowledge tasks, both still having excellent performances.
| Benchmark | gpt-oss-120b | gpt-oss-20b | OpenAI o3 | OpenAI o4-mini |
|---|---|---|---|---|
| MMLU | 90.0 | 85.3 | 93.4 | 93.0 |
| GPQA Diamond | 80.1 | 71.5 | 83.3 | 81.4 |
| Humanity’s Last Exam | 19.0 | 17.3 | 24.9 | 17.7 |
| AIME 2024 | 96.6 | 96.0 | 95.2 | 98.7 |
| AIME 2025 | 97.9 | 98.7 | 98.4 | 99.5 |
Use Cases and Applications
Here are some applications for gpt-oss:
- Content Generation and Rewriting: Generate or rewrite articles, stories, or marketing copy. These models can describe their thought process before writing and assist writers and journalists in developing better content.
- Tutoring and Education: can demonstrate different ways to describe a concept, walk through problems step by step, and provide feedback to educational apps or tutoring tools, and medicine.
- Code Generation: can generate code, debug code, or explain code very well. Models can also internally execute tools, allowing them to be helpful with related development tasks or as coding assistants.
- Research Assistance: can summarize documents, respond to domain-specific questions, and analyze data. The larger models can also be fine-tuned for specific fields of study, such as law, medicine, or science.
- Autonomous Agents: Enables actions that use tools to build bots with autonomous agents that can browse the web, call APIs, or run code. Integrates easily with agent frameworks to build more complex step-based workflows.
Conclusion
The 120B model clearly outperforms across the board: generating sharper content, solving harder problems, writing better code, and adapting faster in research and autonomous tasks. Its only real tradeoff is resource intensity, which makes local deployment a challenge. But if you’ve got the infrastructure, there’s no contest. This isn’t just an upgrade! It’s a whole new tier of capability.
Hello! I’m Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I’m eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.
Login to continue reading and enjoy expert-curated content.