
{kind=link}
Additional Post Contributors: Maxime Peim, Benoit Ganne
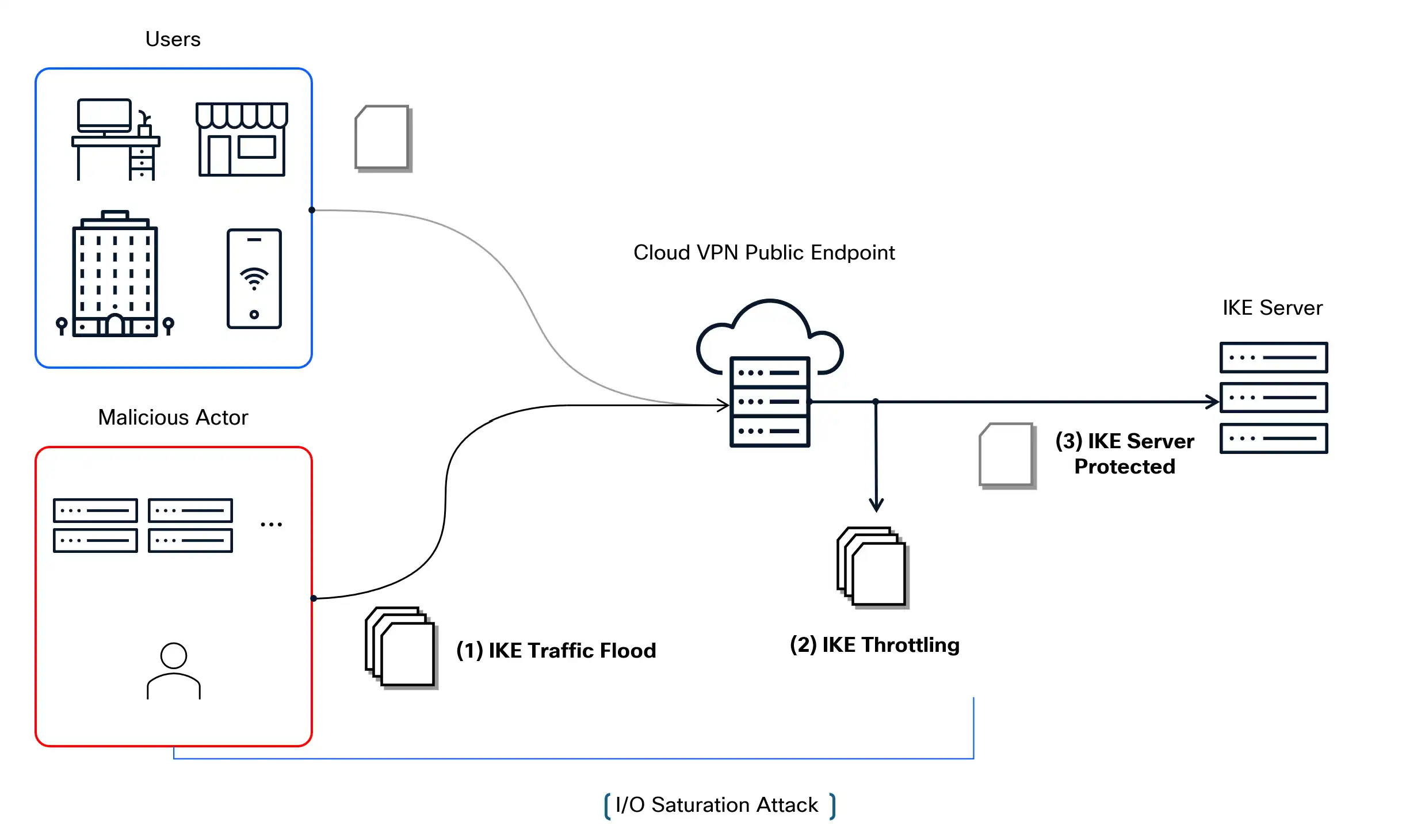
Cloud-VPN & IKEv2 endpoints exposition to DoS attacks
Cloud-based VPN solutions commonly expose IKEv2 (Internet Key Exchange v2) endpoints to the public Internet to support scalable, on-demand tunnel establishment for customers. While this enables flexibility and broad accessibility, it also significantly increases the attack surface. These publicly reachable endpoints become attractive targets for Denial-of-Service (DoS) attacks, wherein adversaries can flood the key exchange servers with a high volume of IKE traffic.
Beyond the computational and memory overhead involved in handling large numbers of session initiations, such attacks can impose severe stress on the underlying system through extreme packet I/O rates, even before reaching the application layer. The combined effect of I/O saturation and protocol-level processing can lead to resource exhaustion, thereby preventing legitimate users from establishing new tunnels or maintaining existing ones — ultimately undermining the availability and reliability of the VPN service.

Implementing a network-layer throttling mechanism
To enhance the resilience of our infrastructure against IKE-targeted DoS attacks, we implemented a generalized throttling mechanism at the network layer to limit the rate of IKE session initiations per source IP, without impacting IKE traffic associated with established tunnels. This approach reduces the processing burden on IKE servers by proactively filtering excessive traffic before it reaches the IKE server. In parallel, we deployed a tracking system to identify source IPs exhibiting patterns consistent with IKE flooding behavior, enabling rapid response to emerging threats. This network-level mitigation is designed to operate in tandem with complementary protection at the application layer, providing a layered defense strategy against both volumetric and protocol-specific attack vectors.
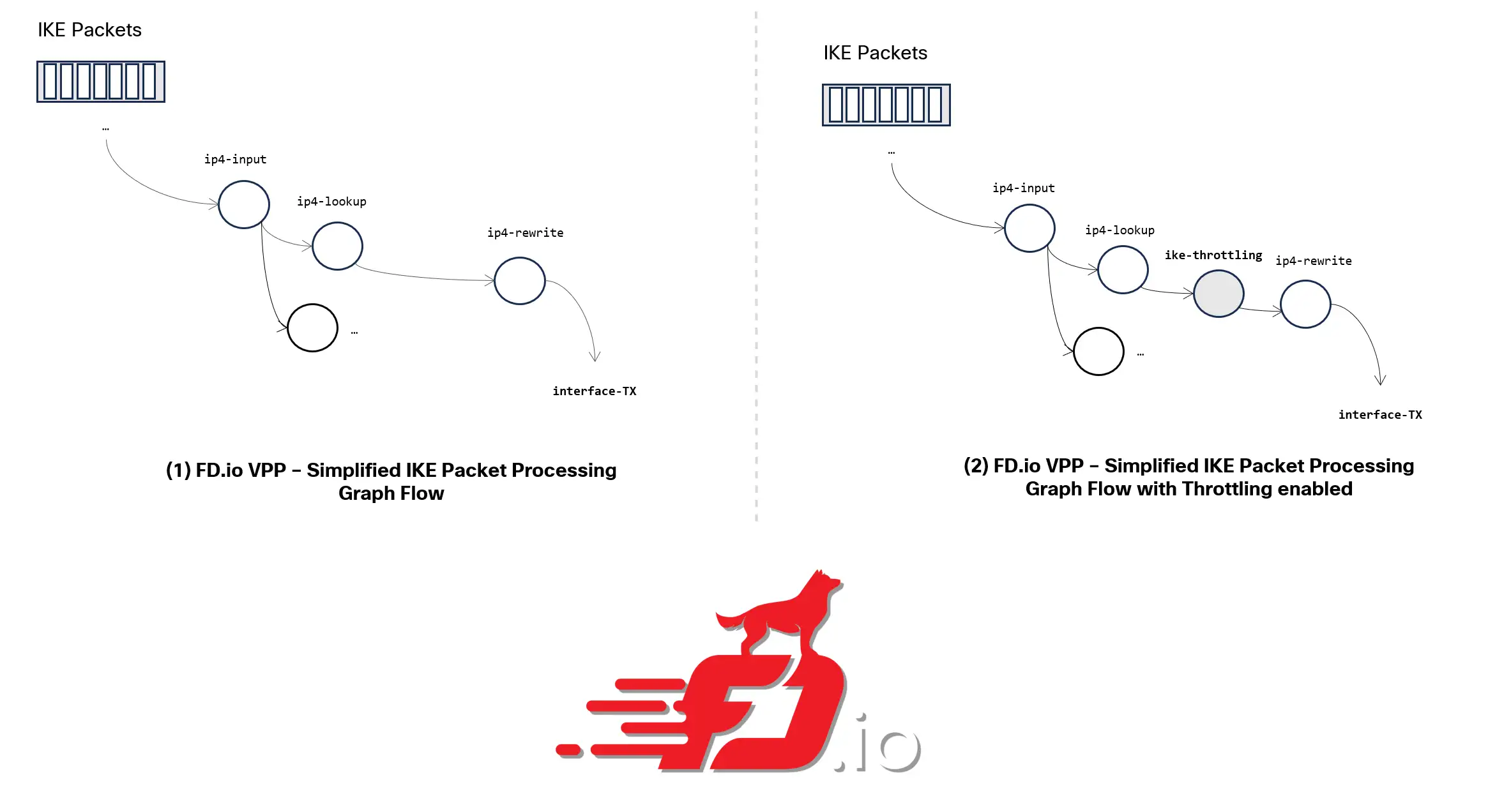
The implementation was done in our data-plane framework (based on FD.io/VPP – Vector Packet processor) by introducing a new node in the packet-processing path for IKE packets.
This custom node leverages the generic throttling mechanism available in VPP, with a balanced approach between memory-efficiency and accuracy: Throttling decisions are taken by inspecting the source IP addresses of incoming IKEv2 packets, processing them into a fixed-size hash table, and verifying if a collision has occurred with previously-seen IPs over the current throttling time interval.

Minimizing the impact on legitimate users
Occasional false positives or unintended over-throttling may occur when distinct source IP addresses collide within the same hash bucket during a given throttling interval. This situation can arise due to hash collisions in the throttling data structure used for rate limiting. However, the practical impact is minimal in the context of IKEv2, as the protocol is inherently resilient to transient failures through its built-in retransmission mechanisms. Additionally, the throttling logic incorporates periodic re-randomization of the hash table seed at the end of each interval. This seed regeneration ensures that the probability of repeated collisions between the same set of source IPs across consecutive intervals remains statistically low, further reducing the likelihood of systematic throttling anomalies.

Providing observability on high-rate initiators with a probabilistic approach
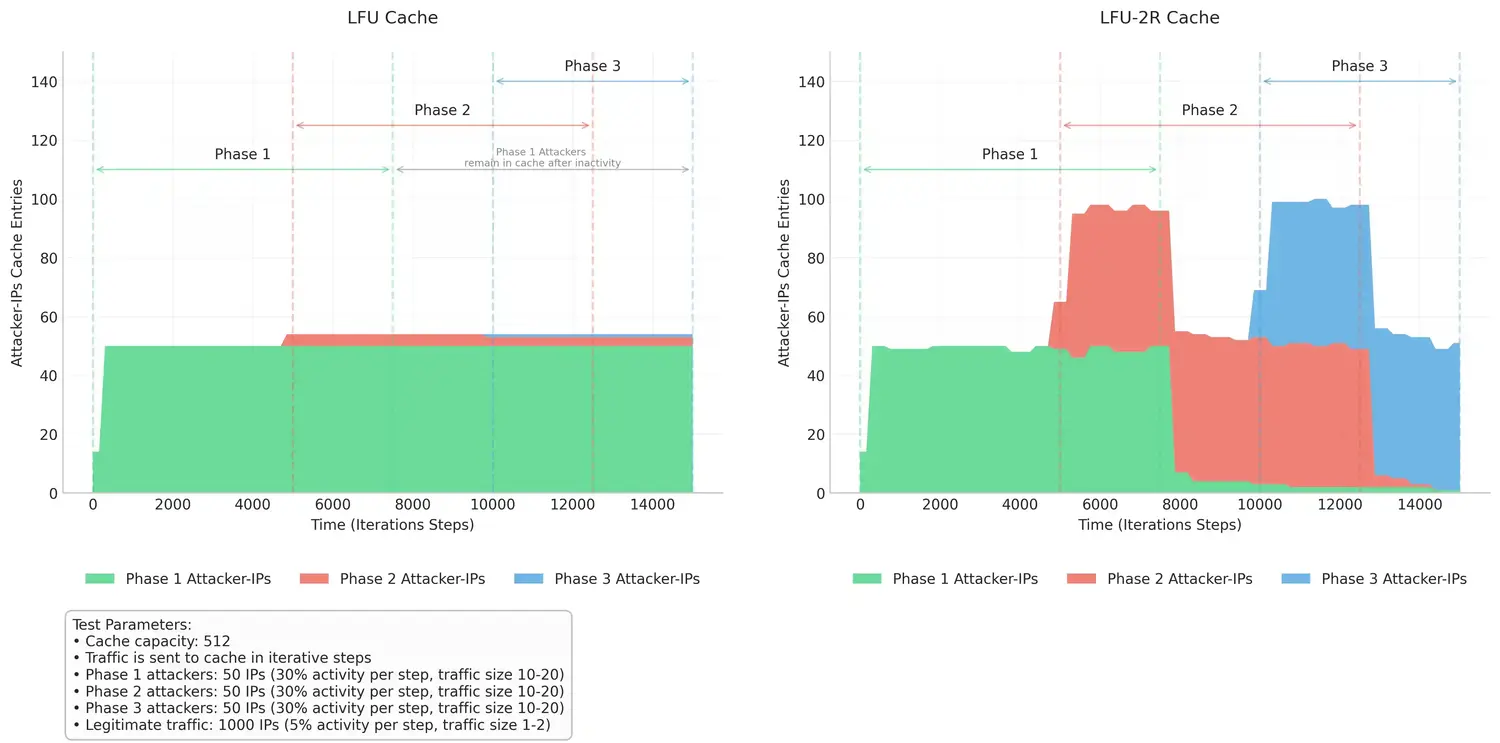
To complement the IKE throttling mechanism, we implemented an observability mechanism that retains metadata on throttled source IPs. This provides critical visibility into high-rate initiators and supports downstream mitigation of workflows. It employs a Least Frequently Used (LFU) 2-Random eviction policy, specifically chosen for its balance between accuracy and computational efficiency under high-load or adversarial conditions such as DoS attacks.
Rather than maintaining a fully ordered frequency list, which would be costly in a high-throughput data plane, LFU 2-Random approximates LFU behavior by randomly sampling two entries from the cache upon eviction and removing the one with the lower access frequency. This probabilistic approach ensures minimal memory and processing overhead, as well as faster adaptation to shifts in DoS traffic patterns, ensuring that attackers with historically high-frequency do not remain in the cache after being inactive for a certain period of time, which would impact observability on more recent active attackers (see Figure-6). The data collected is subsequently leveraged to trigger additional responses during IKE flooding scenarios, such as dynamically blacklisting malicious IPs and identifying legitimate users with potential misconfigurations that generate excessive IKE traffic.
Closing Notes
We encourage similar Cloud-based VPN services and/or services exposing internet-facing IKEv2 server endpoints to proactively investigate similar mitigation mechanisms which would fit their architecture. This would increase systems resiliency to IKE flood attacks at a low computational cost, as well as offers critical visibility into active high-rate initiators to take further actions.
We’d love to hear what you think! Ask a question and stay connected with Cisco Security on social media.
Cisco Security Social Media
Share: